JavaScript で REST API をたたく場合、
XMLHttpRequest, IFRAMEHttpRequest, JSONScriptRequest(JSONP) などを使うわけだが、
Jesterは、
これを抽象化して、xx.find(), xx.save() とかいうカッコいい API を提供してくれる。
そもそも、REST を抽象化して ActiveRecord パターン似の API でやりましょう、
という ActiveResource がRails で提唱・実装されている。
その後、この ActiveResource の実装がいくつか公開されている中で、
クライアントライブラリの JavaScript 実装として有名なのが Jester 。
prototype.js, jQuery なんかの Ajax.foobar() を使ってゴリゴリやるのが今の日本の主流だと思うが、
WebOSGoodies で ActiveResource が絶賛されていることもあり、Jester で軽く試してみた。
Firebug <=> Twitter API
とにかく手軽に試したいので、
- Firebug のコンソール上で Jester を利用
- 既存の REST API である Twitter API を操作
というプランで。
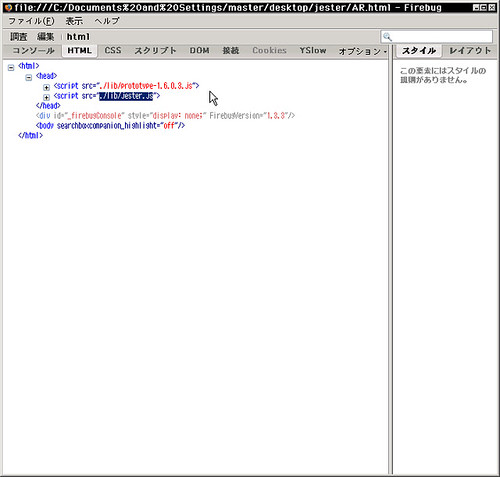
prototype.js, jester.js をロードするだけの HTML を書く。
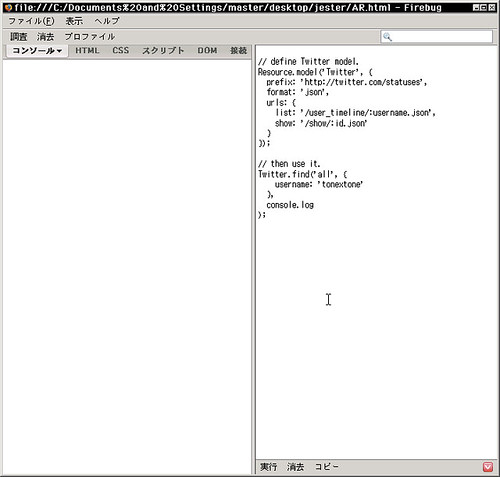
おもむろに使ってみる。find('all' {username: 'tonextone'}, console.log);
DONE!
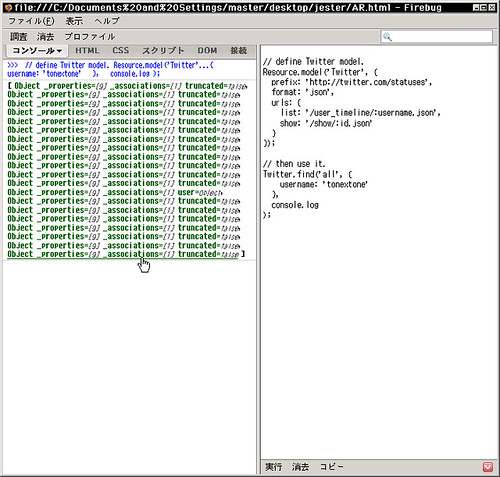
レスポンスの中を見てみる。
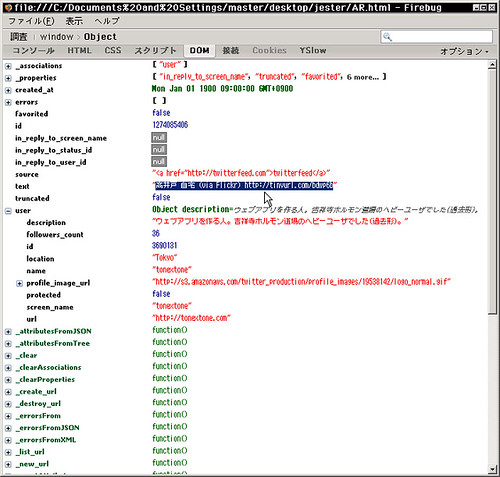
find(1274085406, console.log);

レスポンスの中を見てみる。
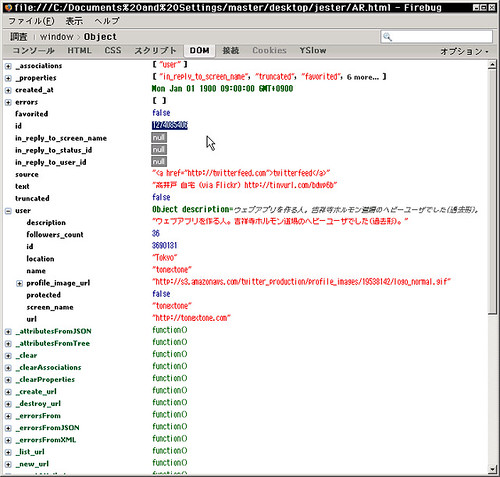
サーバとのやりとりを確認。
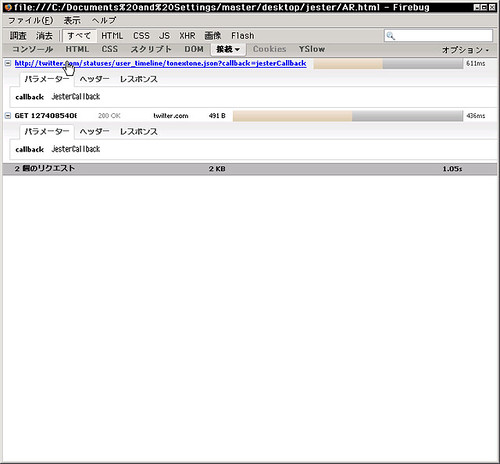
要するに JSONP です。
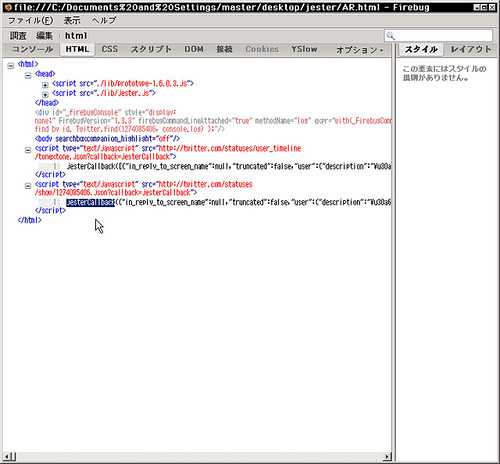
簡単です。お試しあれ。



最近のコメント
└ はじめまして。 現在...
» master on Google Maps API を SSL で使えるようにしてみる。 :
└ そのようです。ご報告...
» kobuchi on Google Maps API を SSL で使えるようにしてみる。 :
└ 今現在、動作していま...
» master on Google Maps API を SSL で使えるようにしてみる。 :
└ あるいは、 Apac...
» master on Google Maps API を SSL で使えるようにしてみる。 :
└ phpinfo() ...
» nabesi on Google Maps API を SSL で使えるようにしてみる。 :
└ SSL経由でGoog...
» master on Google Maps API を SSL で使えるようにしてみる。 :
└ いや、正規表現のパタ...
» master on Google Maps API を SSL で使えるようにしてみる。 :
└ Google の A...
» uriyuri on Google Maps API を SSL で使えるようにしてみる。 :
└ PHPコードを参考に...
» master on 和訳してみた :
└ (独断で)各論過ぎる...